As explained, the clustering method used in package
evprof is Gaussian Mixture Models clustering. This method
is sensible to outliers since it tries to explain as most as possible
all the variance of the data, which results to wide and non-specific
Gaussian distributions (clusters). Therefore evprof
package provides different functions to detect and filter outliers. At
the same time, it is also recommended to perform the clustering process
in a logarithmic scale, to include negative values to originally
positive variables. The logarithmic transformation can be done in most
of functions, setting the log argument to
TRUE.
Here we have a set of sessions of example,
noisy_set:
noisy_set <- sessions_divided %>% # Obtained from the "Get started" article
filter(Disconnection == "Home", Timecycle == "Friday") # Friday Home
plot_points(noisy_set, size = 0.2)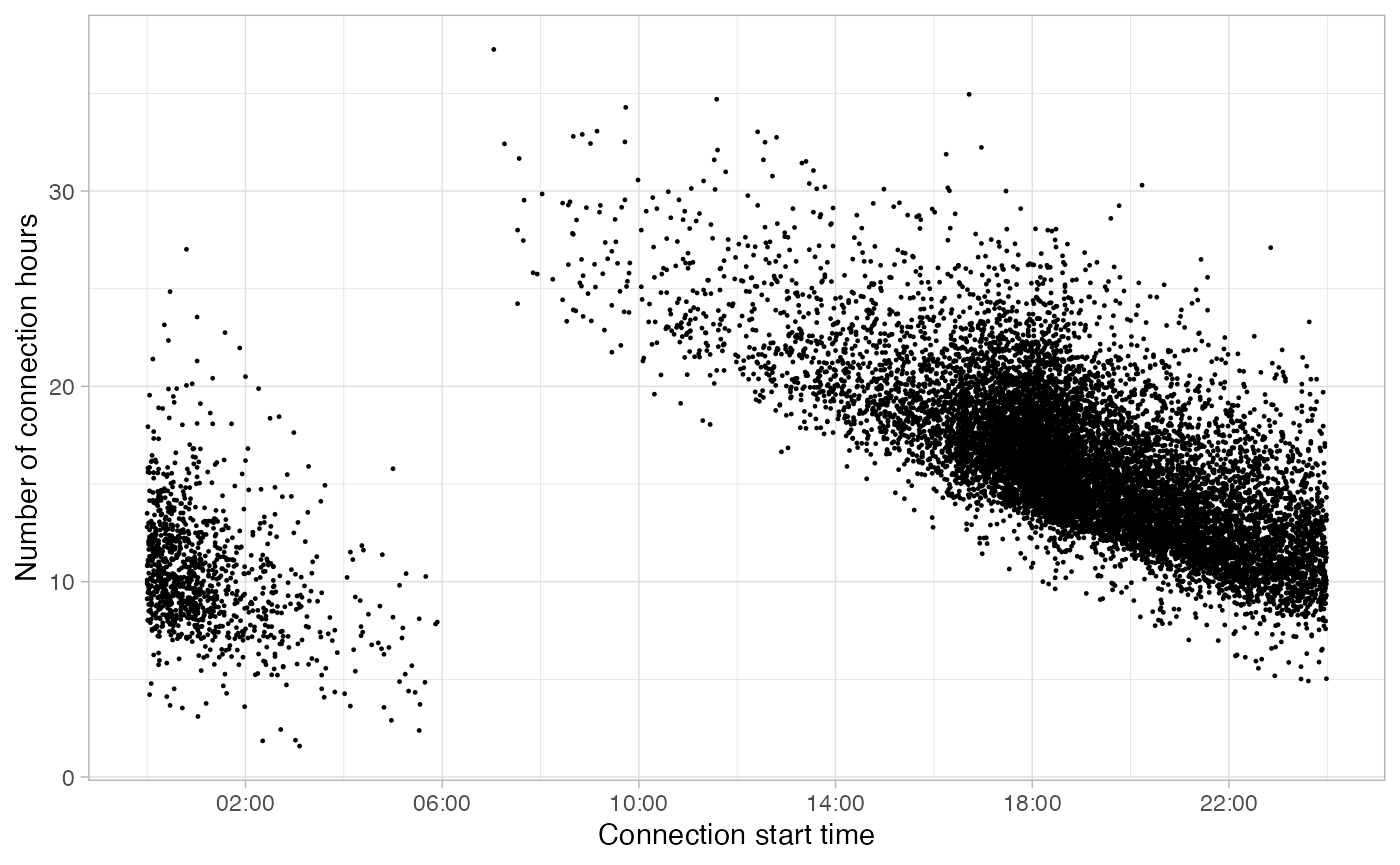
We set the start parameter at 06:00:
options(
evprof.start.hour = 6
)And we can plot it in logarithmic scale to visualize the areas of the plot where outliers are:
plot_points(noisy_set, size = 0.2, log = T)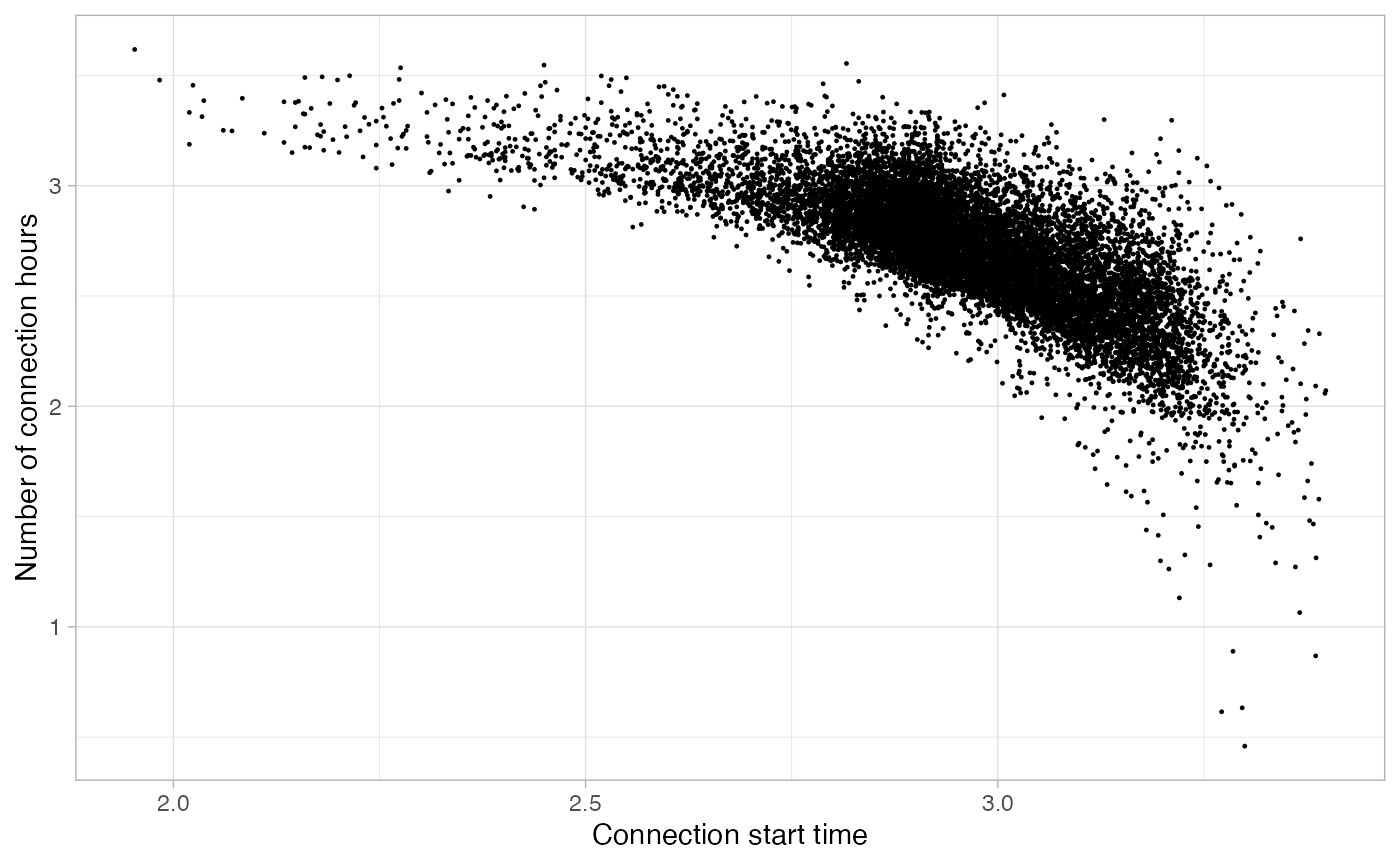
Cutting sessions
If we see a part of the graph that consists clearly of outlying
points, then we can cut directly the sessions below or above this
specific limit using the function cut_sessions(). This
function lets to configure the Connection Duration limits
(connection_hours_min and
connection_hours_max) and the Connection Start limits
(connection_start_min and
connection_start_max). If we want to make the division in
logarithmic scale it is important to set the argument
log = TRUE.
noisy_set <- noisy_set %>%
cut_sessions(connection_hours_min = 1.5, connection_start_min = 2.5, log = T)
plot_points(noisy_set, size = 0.2, log = T)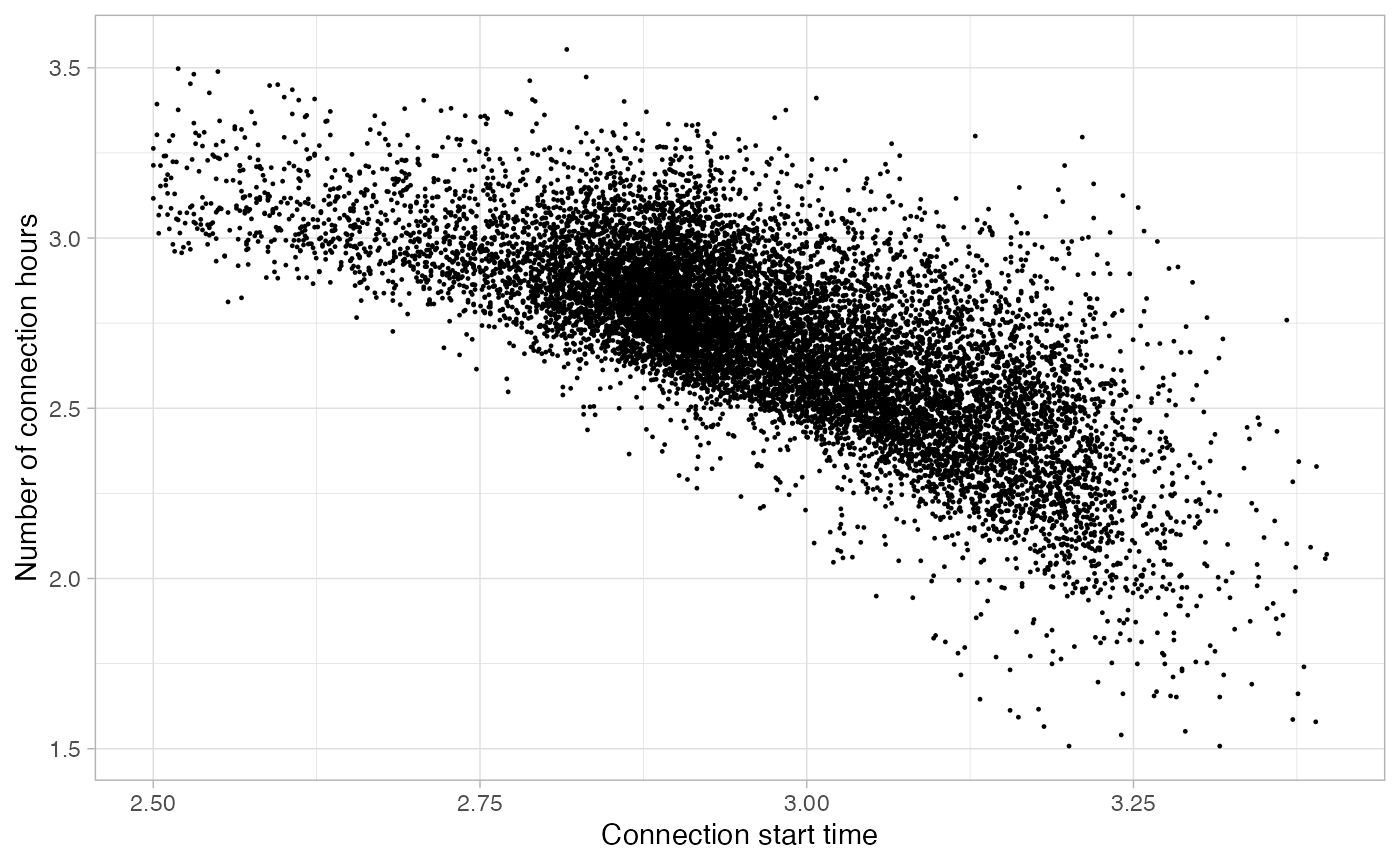
Noise cleaning with DBSCAN clustering
The DBSCAN (Density-based spatial clustering of
applications with noise) clustering method is widely used for dividing
data sets according to density zones. In this case, this method has been
used to detect the outliers, i.e the data points outside of the main
density zones. Package evprof proposes the function
detect_outliers with the purpose of classify a certain
noise threshold of noise. The main arguments of this function
are MinPts, eps (DBSCAN parameters) and
noise_th (noise threshold, in %). The function
detect_outliers allows you to configure just the
MinPts and noise_th to automatically find the
eps value.
Usually values around of MinPts = 200 and
noise_th = 2 are recommended, but you could configure an
iteration to find the best combination according to the plot obtained
with function plot_outliers. First, let’s create a table
with all combinations of MinPts and noise_th
values you want:
.MinPts <- c(10, 50, 100, 200)
.noise_th <- c(1, 3, 5, 7)
dbscan_params <- tibble(
MinPts = rep(.MinPts, each = length(.noise_th)),
noise_th = rep(.noise_th, times = length(.MinPts))
)
print(dbscan_params)Now let’s run the iteration to create a plot for every combination
(using purrr::pmap function):
plots_list <- pmap(
dbscan_params,
~ noisy_set %>%
detect_outliers(MinPts = ..1, noise_th = ..2, log = T) %>%
plot_outliers(log = T, size = 0.2) +
theme(legend.position = "none")
)You can save the plots in a pdf for a proper visualization, using
cowplot::plot_grid function.
ggsave(
filename = 'my_noise_detection.pdf',
plot = cowplot::plot_grid(
plotlist = plots_list, nrow = 4, ncol = 4, labels = as.list(rep(.MinPts, each = length(.noise_th)))
),
width = 500, height = 250, units = "mm"
)From all these plots, we see that the the higher the
MinPts is, the more center-focused is the final clean
cluster. This is not a valid approach for all data sets, so the value of
MinPts must be defined properly in every case. In this
case, we decide that a good compromise solution is a value of
MinPts of 200 and a noise threshold of
5%:
plots_list[[15]]## $data
## # A tibble: 12,946 × 14
## Session ConnectionStartDateTime ConnectionEndDateTime ChargingStartDateTime
## <chr> <dbl> <dttm> <dttm>
## 1 87420 2.82 2015-09-05 08:25:00 2015-09-04 16:45:00
## 2 87415 2.85 2015-09-05 12:29:00 2015-09-04 17:14:00
## 3 87417 2.85 2015-09-05 11:30:00 2015-09-04 17:22:00
## 4 87424 2.87 2015-09-05 15:35:00 2015-09-04 17:37:00
## 5 87425 2.87 2015-09-05 11:25:00 2015-09-04 17:37:00
## 6 87439 2.91 2015-09-05 07:53:00 2015-09-04 18:17:00
## 7 87449 2.91 2015-09-05 08:38:00 2015-09-04 18:24:00
## 8 87451 2.92 2015-09-05 10:02:00 2015-09-04 18:33:00
## 9 87483 3.01 2015-09-05 07:44:00 2015-09-04 20:22:00
## 10 87484 3.02 2015-09-05 16:30:00 2015-09-04 20:28:00
## # ℹ 12,936 more rows
## # ℹ 10 more variables: ChargingEndDateTime <dttm>, Power <dbl>, Energy <dbl>,
## # ConnectionHours <dbl>, ChargingHours <dbl>, FlexibilityHours <dbl>,
## # ChargingStation <chr>, Disconnection <fct>, Timecycle <fct>, Outlier <lgl>
##
## $layers
## $layers[[1]]
## geom_point: na.rm = FALSE
## stat_identity: na.rm = FALSE
## position_identity
##
##
## $scales
## <ggproto object: Class ScalesList, gg>
## add: function
## add_defaults: function
## add_missing: function
## backtransform_df: function
## clone: function
## find: function
## get_scales: function
## has_scale: function
## input: function
## map_df: function
## n: function
## non_position_scales: function
## scales: list
## set_palettes: function
## train_df: function
## transform_df: function
## super: <ggproto object: Class ScalesList, gg>
##
## $guides
## <Guides[1] ggproto object>
##
## colour : <GuideLegend>
##
## $mapping
## $x
## <quosure>
## expr: ^.data[["ConnectionStartDateTime"]]
## env: 0x133e44b80
##
## $y
## <quosure>
## expr: ^.data[["ConnectionHours"]]
## env: 0x133e44b80
##
## $colour
## <quosure>
## expr: ^.data[["Outlier"]]
## env: 0x133e44b80
##
## attr(,"class")
## [1] "uneval"
##
## $theme
## $line
## $colour
## [1] "black"
##
## $linewidth
## [1] 0.5
##
## $linetype
## [1] 1
##
## $lineend
## [1] "butt"
##
## $arrow
## [1] FALSE
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_line" "element"
##
## $rect
## $fill
## [1] "white"
##
## $colour
## [1] "black"
##
## $linewidth
## [1] 0.5
##
## $linetype
## [1] 1
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_rect" "element"
##
## $text
## $family
## [1] ""
##
## $face
## [1] "plain"
##
## $colour
## [1] "black"
##
## $size
## [1] 11
##
## $hjust
## [1] 0.5
##
## $vjust
## [1] 0.5
##
## $angle
## [1] 0
##
## $lineheight
## [1] 0.9
##
## $margin
## [1] 0points 0points 0points 0points
##
## $debug
## [1] FALSE
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $title
## NULL
##
## $aspect.ratio
## NULL
##
## $axis.title
## NULL
##
## $axis.title.x
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## [1] 1
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 2.75points 0points 0points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.title.x.top
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## [1] 0
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 0points 2.75points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.title.x.bottom
## NULL
##
## $axis.title.y
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## [1] 1
##
## $angle
## [1] 90
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 2.75points 0points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.title.y.left
## NULL
##
## $axis.title.y.right
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## [1] 1
##
## $angle
## [1] -90
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 0points 0points 2.75points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.text
## $family
## NULL
##
## $face
## NULL
##
## $colour
## [1] "grey30"
##
## $size
## [1] 0.8 *
##
## $hjust
## NULL
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## NULL
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.text.x
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## [1] 1
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 2.2points 0points 0points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.text.x.top
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## [1] 0
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 0points 2.2points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.text.x.bottom
## NULL
##
## $axis.text.y
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## [1] 1
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 2.2points 0points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.text.y.left
## NULL
##
## $axis.text.y.right
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## [1] 0
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 0points 0points 2.2points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.text.theta
## NULL
##
## $axis.text.r
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## [1] 0.5
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 2.2points 0points 2.2points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $axis.ticks
## $colour
## [1] "grey70"
##
## $linewidth
## [1] 0.5 *
##
## $linetype
## NULL
##
## $lineend
## NULL
##
## $arrow
## [1] FALSE
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_line" "element"
##
## $axis.ticks.x
## NULL
##
## $axis.ticks.x.top
## NULL
##
## $axis.ticks.x.bottom
## NULL
##
## $axis.ticks.y
## NULL
##
## $axis.ticks.y.left
## NULL
##
## $axis.ticks.y.right
## NULL
##
## $axis.ticks.theta
## NULL
##
## $axis.ticks.r
## NULL
##
## $axis.minor.ticks.x.top
## NULL
##
## $axis.minor.ticks.x.bottom
## NULL
##
## $axis.minor.ticks.y.left
## NULL
##
## $axis.minor.ticks.y.right
## NULL
##
## $axis.minor.ticks.theta
## NULL
##
## $axis.minor.ticks.r
## NULL
##
## $axis.ticks.length
## [1] 2.75points
##
## $axis.ticks.length.x
## NULL
##
## $axis.ticks.length.x.top
## NULL
##
## $axis.ticks.length.x.bottom
## NULL
##
## $axis.ticks.length.y
## NULL
##
## $axis.ticks.length.y.left
## NULL
##
## $axis.ticks.length.y.right
## NULL
##
## $axis.ticks.length.theta
## NULL
##
## $axis.ticks.length.r
## NULL
##
## $axis.minor.ticks.length
## [1] 0.75 *
##
## $axis.minor.ticks.length.x
## NULL
##
## $axis.minor.ticks.length.x.top
## NULL
##
## $axis.minor.ticks.length.x.bottom
## NULL
##
## $axis.minor.ticks.length.y
## NULL
##
## $axis.minor.ticks.length.y.left
## NULL
##
## $axis.minor.ticks.length.y.right
## NULL
##
## $axis.minor.ticks.length.theta
## NULL
##
## $axis.minor.ticks.length.r
## NULL
##
## $axis.line
## list()
## attr(,"class")
## [1] "element_blank" "element"
##
## $axis.line.x
## NULL
##
## $axis.line.x.top
## NULL
##
## $axis.line.x.bottom
## NULL
##
## $axis.line.y
## NULL
##
## $axis.line.y.left
## NULL
##
## $axis.line.y.right
## NULL
##
## $axis.line.theta
## NULL
##
## $axis.line.r
## NULL
##
## $legend.background
## $fill
## NULL
##
## $colour
## [1] NA
##
## $linewidth
## NULL
##
## $linetype
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_rect" "element"
##
## $legend.margin
## [1] 5.5points 5.5points 5.5points 5.5points
##
## $legend.spacing
## [1] 11points
##
## $legend.spacing.x
## NULL
##
## $legend.spacing.y
## NULL
##
## $legend.key
## NULL
##
## $legend.key.size
## [1] 1.2lines
##
## $legend.key.height
## NULL
##
## $legend.key.width
## NULL
##
## $legend.key.spacing
## [1] 5.5points
##
## $legend.key.spacing.x
## NULL
##
## $legend.key.spacing.y
## NULL
##
## $legend.frame
## NULL
##
## $legend.ticks
## NULL
##
## $legend.ticks.length
## [1] 0.2 *
##
## $legend.axis.line
## NULL
##
## $legend.text
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## [1] 0.8 *
##
## $hjust
## NULL
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## NULL
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $legend.text.position
## NULL
##
## $legend.title
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## [1] 0
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## NULL
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $legend.title.position
## NULL
##
## $legend.position
## [1] "none"
##
## $legend.position.inside
## NULL
##
## $legend.direction
## NULL
##
## $legend.byrow
## NULL
##
## $legend.justification
## [1] "center"
##
## $legend.justification.top
## NULL
##
## $legend.justification.bottom
## NULL
##
## $legend.justification.left
## NULL
##
## $legend.justification.right
## NULL
##
## $legend.justification.inside
## NULL
##
## $legend.location
## NULL
##
## $legend.box
## NULL
##
## $legend.box.just
## NULL
##
## $legend.box.margin
## [1] 0cm 0cm 0cm 0cm
##
## $legend.box.background
## list()
## attr(,"class")
## [1] "element_blank" "element"
##
## $legend.box.spacing
## [1] 11points
##
## $panel.background
## $fill
## [1] "white"
##
## $colour
## [1] NA
##
## $linewidth
## NULL
##
## $linetype
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_rect" "element"
##
## $panel.border
## $fill
## [1] NA
##
## $colour
## [1] "grey70"
##
## $linewidth
## [1] 1 *
##
## $linetype
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_rect" "element"
##
## $panel.spacing
## [1] 5.5points
##
## $panel.spacing.x
## NULL
##
## $panel.spacing.y
## NULL
##
## $panel.grid
## $colour
## [1] "grey87"
##
## $linewidth
## NULL
##
## $linetype
## NULL
##
## $lineend
## NULL
##
## $arrow
## [1] FALSE
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_line" "element"
##
## $panel.grid.major
## $colour
## NULL
##
## $linewidth
## [1] 0.5 *
##
## $linetype
## NULL
##
## $lineend
## NULL
##
## $arrow
## [1] FALSE
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_line" "element"
##
## $panel.grid.minor
## $colour
## NULL
##
## $linewidth
## [1] 0.25 *
##
## $linetype
## NULL
##
## $lineend
## NULL
##
## $arrow
## [1] FALSE
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_line" "element"
##
## $panel.grid.major.x
## NULL
##
## $panel.grid.major.y
## NULL
##
## $panel.grid.minor.x
## NULL
##
## $panel.grid.minor.y
## NULL
##
## $panel.ontop
## [1] FALSE
##
## $plot.background
## $fill
## NULL
##
## $colour
## [1] "white"
##
## $linewidth
## NULL
##
## $linetype
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_rect" "element"
##
## $plot.title
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## [1] 1.2 *
##
## $hjust
## [1] 0
##
## $vjust
## [1] 1
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 0points 5.5points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $plot.title.position
## [1] "panel"
##
## $plot.subtitle
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## [1] 0
##
## $vjust
## [1] 1
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 0points 0points 5.5points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $plot.caption
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## [1] 0.8 *
##
## $hjust
## [1] 1
##
## $vjust
## [1] 1
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 5.5points 0points 0points 0points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $plot.caption.position
## [1] "panel"
##
## $plot.tag
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## [1] 1.2 *
##
## $hjust
## [1] 0.5
##
## $vjust
## [1] 0.5
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## NULL
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $plot.tag.position
## [1] "topleft"
##
## $plot.tag.location
## NULL
##
## $plot.margin
## [1] 5.5points 5.5points 5.5points 5.5points
##
## $strip.background
## $fill
## [1] "grey70"
##
## $colour
## [1] NA
##
## $linewidth
## NULL
##
## $linetype
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_rect" "element"
##
## $strip.background.x
## NULL
##
## $strip.background.y
## NULL
##
## $strip.clip
## [1] "inherit"
##
## $strip.placement
## [1] "inside"
##
## $strip.text
## $family
## NULL
##
## $face
## NULL
##
## $colour
## [1] "white"
##
## $size
## [1] 0.8 *
##
## $hjust
## NULL
##
## $vjust
## NULL
##
## $angle
## NULL
##
## $lineheight
## NULL
##
## $margin
## [1] 4.4points 4.4points 4.4points 4.4points
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $strip.text.x
## NULL
##
## $strip.text.x.bottom
## NULL
##
## $strip.text.x.top
## NULL
##
## $strip.text.y
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## NULL
##
## $angle
## [1] -90
##
## $lineheight
## NULL
##
## $margin
## NULL
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $strip.text.y.left
## $family
## NULL
##
## $face
## NULL
##
## $colour
## NULL
##
## $size
## NULL
##
## $hjust
## NULL
##
## $vjust
## NULL
##
## $angle
## [1] 90
##
## $lineheight
## NULL
##
## $margin
## NULL
##
## $debug
## NULL
##
## $inherit.blank
## [1] TRUE
##
## attr(,"class")
## [1] "element_text" "element"
##
## $strip.text.y.right
## NULL
##
## $strip.switch.pad.grid
## [1] 2.75points
##
## $strip.switch.pad.wrap
## [1] 2.75points
##
## attr(,"class")
## [1] "theme" "gg"
## attr(,"complete")
## [1] TRUE
## attr(,"validate")
## [1] TRUE
##
## $coordinates
## <ggproto object: Class CoordCartesian, Coord, gg>
## aspect: function
## backtransform_range: function
## clip: on
## default: TRUE
## distance: function
## draw_panel: function
## expand: TRUE
## is_free: function
## is_linear: function
## labels: function
## limits: list
## modify_scales: function
## range: function
## render_axis_h: function
## render_axis_v: function
## render_bg: function
## render_fg: function
## reverse: none
## setup_data: function
## setup_layout: function
## setup_panel_guides: function
## setup_panel_params: function
## setup_params: function
## train_panel_guides: function
## transform: function
## super: <ggproto object: Class CoordCartesian, Coord, gg>
##
## $facet
## <ggproto object: Class FacetNull, Facet, gg>
## attach_axes: function
## attach_strips: function
## compute_layout: function
## draw_back: function
## draw_front: function
## draw_labels: function
## draw_panel_content: function
## draw_panels: function
## finish_data: function
## format_strip_labels: function
## init_gtable: function
## init_scales: function
## map_data: function
## params: list
## set_panel_size: function
## setup_data: function
## setup_panel_params: function
## setup_params: function
## shrink: TRUE
## train_scales: function
## vars: function
## super: <ggproto object: Class FacetNull, Facet, gg>
##
## $plot_env
## <environment: 0x133e44b80>
##
## $layout
## <ggproto object: Class Layout, gg>
## coord: NULL
## coord_params: list
## facet: NULL
## facet_params: list
## finish_data: function
## get_scales: function
## layout: NULL
## map_position: function
## panel_params: NULL
## panel_scales_x: NULL
## panel_scales_y: NULL
## render: function
## render_labels: function
## reset_scales: function
## resolve_label: function
## setup: function
## setup_panel_guides: function
## setup_panel_params: function
## train_position: function
## super: <ggproto object: Class Layout, gg>
##
## $labels
## $labels$x
## [1] "Connection start time"
##
## $labels$y
## [1] "Number of connection hours"
##
## $labels$colour
## [1] ""
##
## $labels$subtitle
## [1] "Outliers level: 5.09 %"
##
##
## attr(,"class")
## [1] "gg" "ggplot"